Neuromorphic Audio Front-End
µWatts Voice & Sound Classification
with WhisperExtractor
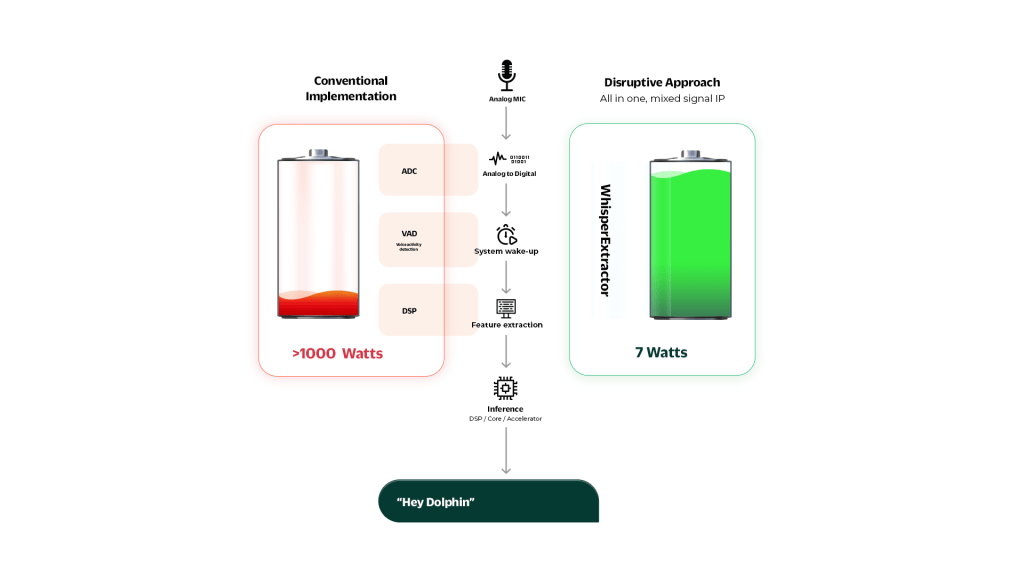
WhisperExtractor is a disruptive technology addressing a major challenge in the voice-user interaction space – low power consumption.
With the increasing adoption of voice user interfaces in everyday objects, it has become critical to have efficient and low-power solutions for voice processing. Conventional digital signal processing methods to process MFCC require a significant amount of energy to convert analog signals to digital and perform signal processing calculations, making it difficult to implement always-on voice listening without draining the battery.
32 kHz RC Clock
Always on domain friendly.
Only 7 µWatts
Near-zero power consumption
Seamless Integration
No software required
Evaluation kit available
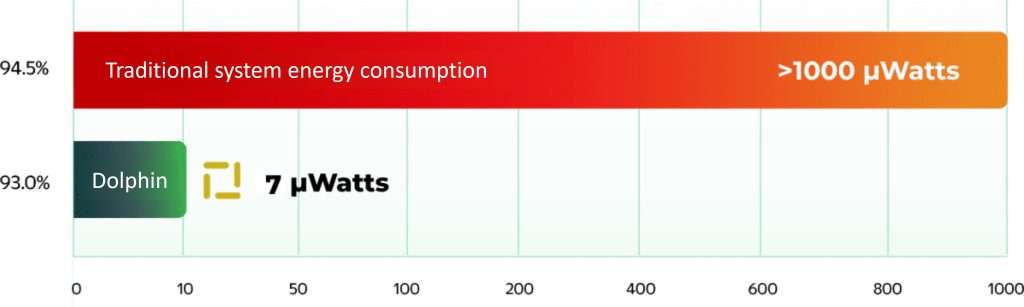
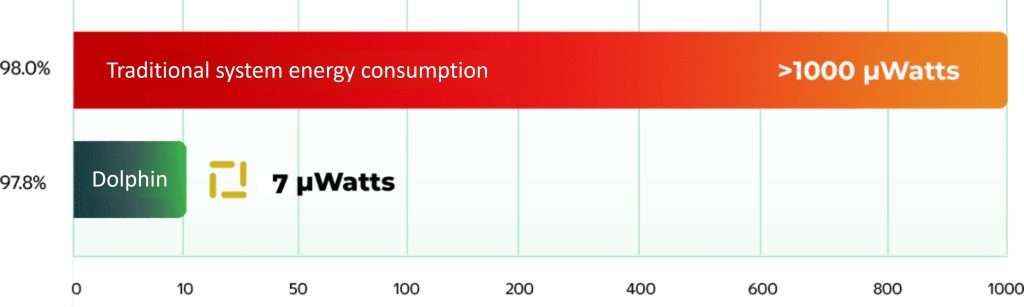
Up to 99% Energy Saving while Maintaining Inference Accuracy
Google Speech Command (20 words) - accuracy
Chinese KWS (25 words) - accuracy
Benefits
With its mixed-signal architecture, the WhisperExtractor is able to efficiently extract the Mel Frequency Cepstrum Coefficients (MFCC) needed for voice processing like you would usually do on a DSP. The output data of the WhisperExtractor is fully compatible with modern machine learning models and accelerators, including CNNs and RNNs.
This means that it is a versatile solution that can be easily integrated into a wide range of applications, from smart home devices to wearables and beyond.
- Revolutionary technology in voice interaction.
- Provides low-power voice processing and always-on listening.
- Unleashes a world of possibilities for developers and manufacturers of innovative products.
- A must-have solution for revolutionizing the voice user experience and staying ahead of the competition.
